
In Russia
The system processes two-hour videos or hundreds of pages of documents within a 256,000-token context window. The flagship model detects target frames in 30-minute videos with nearly 100% accuracy.
In benchmarks, Qwen3-VL-235B-A22B often surpasses Gemini 2.5 Pro and GPT-5. The model dominates visual mathematical reasoning tasks, scoring 85.8% on MathVista (GPT-5 scores 81.3%) and leading on MathVision.
Alibaba implemented three key upgrades:
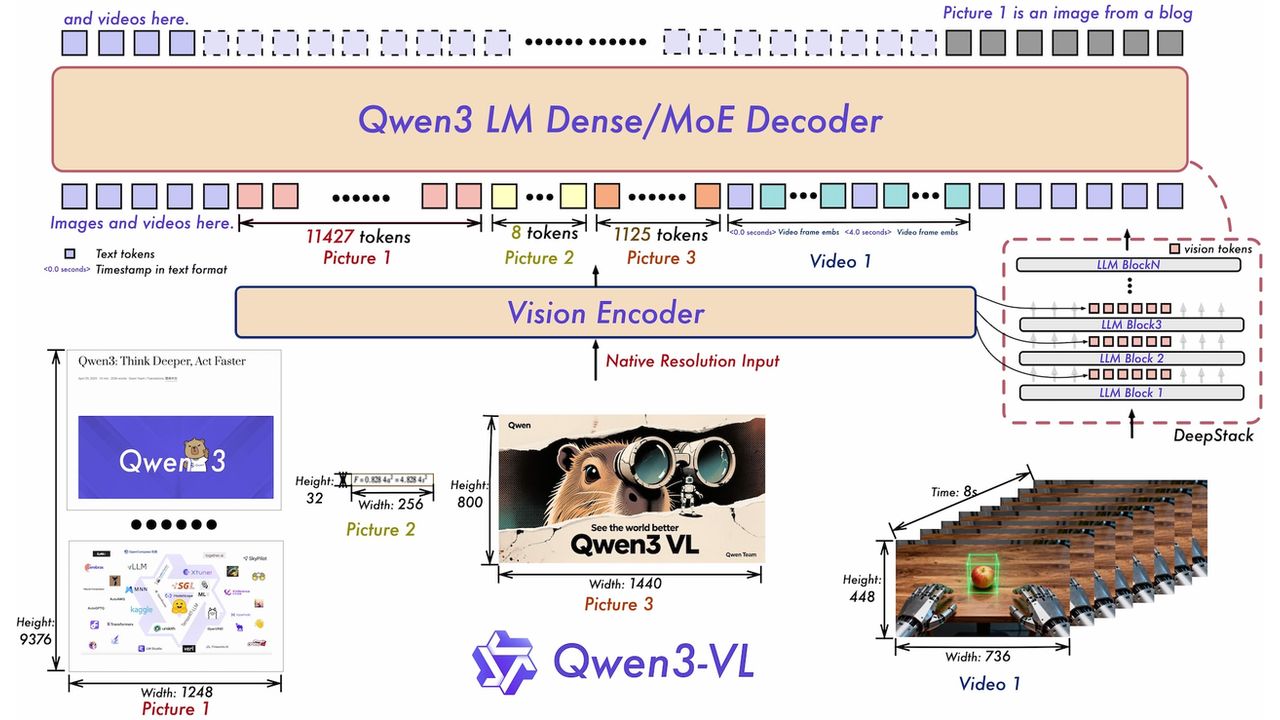
✔️ Interleaved MRoPE: a new positional-embedding method that improves performance on long videos
✔️ DeepStack: allows the model to access intermediate outputs of the video encoder to analyze visual information at different levels of detail
✔️ Text-based temporal tags: a simplified video-frame labeling system that improves understanding of temporal tasks
